书生・浦语 2.0(InternLM2)大语言模型正式开源
1 月 17 日,书生・浦语 2.0(InternLM2)发布会暨书生・浦源大模型挑战赛启动仪式在上海举行。上海人工智能实验室与商汤科技联合香港中文大学和复旦大学正式发布新一代大语言模型书⽣・浦语 2.0(InternLM2)。
据介绍,InternLM2 是在 2.6 万亿 token 的高质量语料上训练得到的。沿袭第一代书生・浦语(InternLM)的设定,InternLM2 包含 7B 及 20B 两种参数规格及基座、对话等版本,满足不同复杂应用场景需求。秉持 “以高质量开源赋能创新” 理念,上海 AI 实验室继续提供 InternLM2 免费商用授权。
InternLM2 的核心理念在于回归语言建模的本质,致力于通过提高语料质量及信息密度,实现模型基座语言建模能力获得质的提升,进而在数理、代码、对话、创作等各方面都取得长足进步,综合性能达到同量级开源模型的领先水平。其支持 200K token 的上下文,一次性接收并处理约 30 万汉字的输入内容,准确提取关键信息,实现长文本中 “大海捞针”。
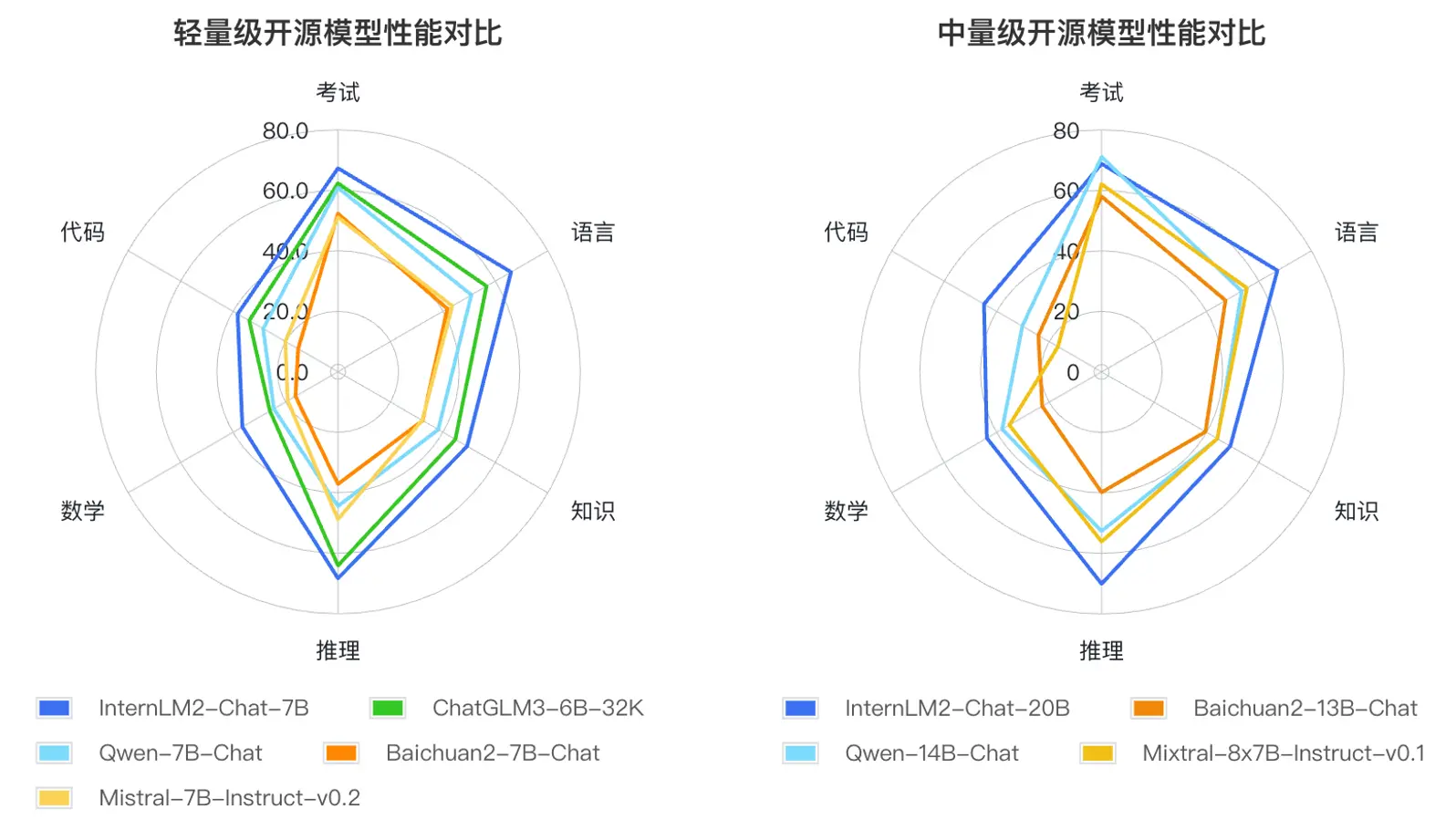
此外,InternLM2 的各项能力获得全面进步,相比于初代 InternLM,在推理、数学、代码等方面的能力提升尤为显著,综合能力领先于同量级开源模型。
根据大语言模型的应用方式和用户关注的重点领域,研究人员定义了语言、知识、推理、数学、代码、考试等六个能力维度,在 55 个主流评测集上对多个同量级模型的表现进行了综合评测。评测结果显示,InternLM2 的轻量级(7B)及中量级(20B)版本性能在同量级模型中表现优异。
开源地址
- Github:https://github.com/InternLM/InternLM
- HuggingFace:https://huggingface.co/internlm
- ModelScope:https://modelscope.cn/organization/Shanghai_AI_Laboratory
主播点评:现在AI大模型真是“乱花渐欲迷人眼”,层出不穷啊。
广而告之:欢迎注册币安BINANCE虚拟货币交易所!
